Datafusion Comet (part3) transform
#datafusion #comet #spark #sparkplan #sparkrule
This blog post is work in progress with its content, accuracy, and of course, formatting.
QA
How to execute the data format transition for fallback or transform native
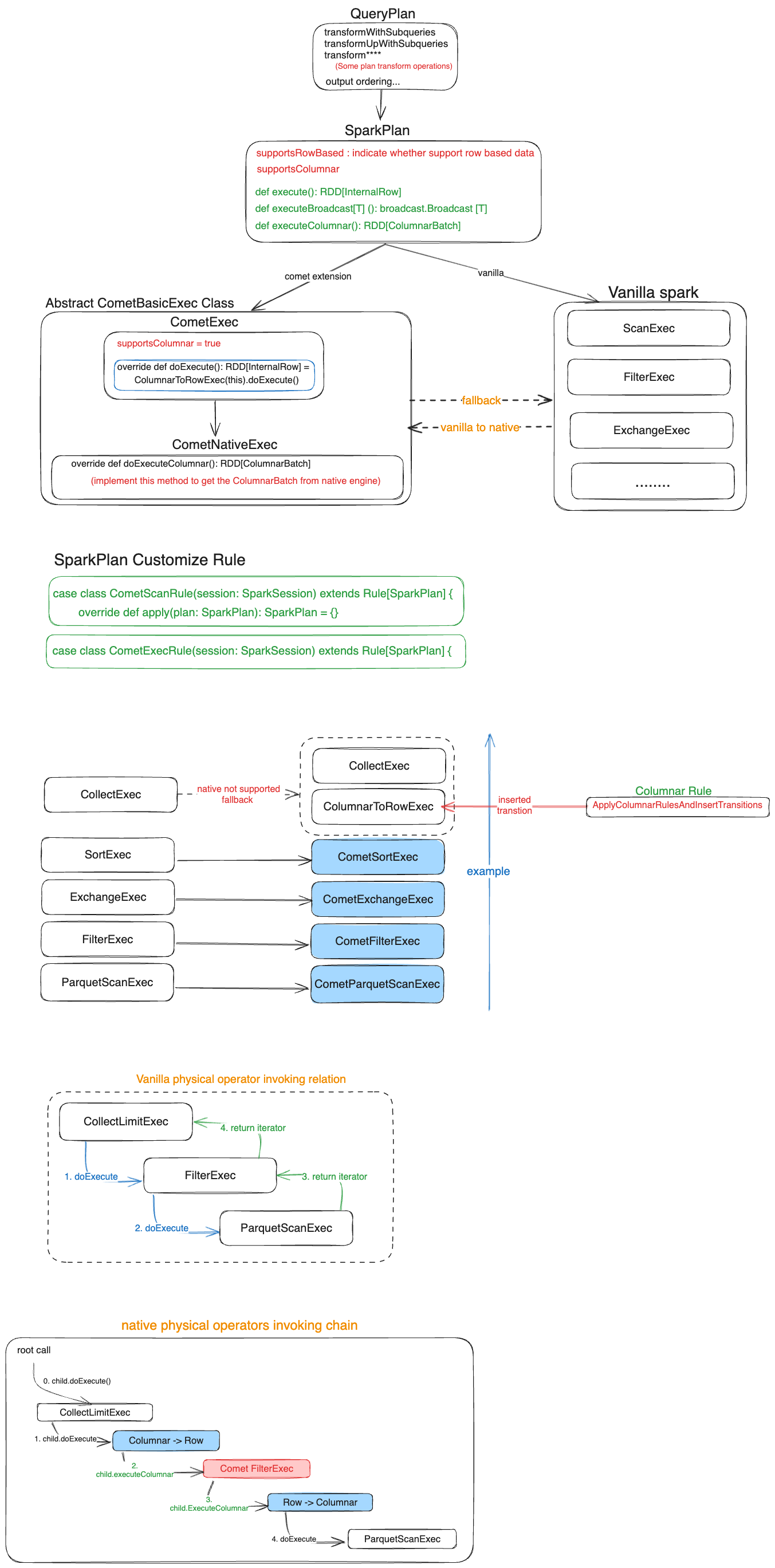
For the case of transform from vanilla operators to native operators (vice versa), this should be applied by the comet exec rule that is extended the pluggable spark's rule.
But this only do the plan replacement for these supported native operators. The data format transition like row-based to columnar won't be shown here.
If the operator (or plan or exec) is not supported columnarBatch or row-based(checked by the supportsColumnar variable), the ApplyColumnarRulesAndInsertTransitions will insert the transition nodes(Row->Columnar or Columnar->Row) in the spark plan. (This should be found on the https://github.com/apache/spark/blob/14d3f447360b66663c8979a8cdb4c40c480a1e04/sql/core/src/main/scala/org/apache/spark/sql/execution/Columnar.scala#L492-L545)
But for some corner cases, the comet also implement their own RowToColumnarExec, please see the issue: https://github.com/apache/datafusion-comet/issues/119
For any operators, the concrete execution is invoked by the parent operators, that means the
Whiteboard